Get Started with Dgraph - Fuzzy Search
Welcome to the seventh tutorial of getting started with Dgraph.
In the previous tutorial, we learned about
building advanced text searches on social graphs in Dgraph, by modeling tweets
as an example.
We queried the tweets using the fulltext and trigram indices and implemented
full-text and regular expression search on the tweets.
In this tutorial, we’ll continue exploring Dgraph’s string querying
capabilities using the twitter model from the fifth
and the sixth tutorials. In particular,
we’ll implement a twitter username search feature using the Dgraph’s
fuzzy search function.
The accompanying video of the tutorial will be out shortly, so stay tuned to our YouTube channel.
Before we dive in, let’s review of how we modeled the tweets in the previous two tutorials:
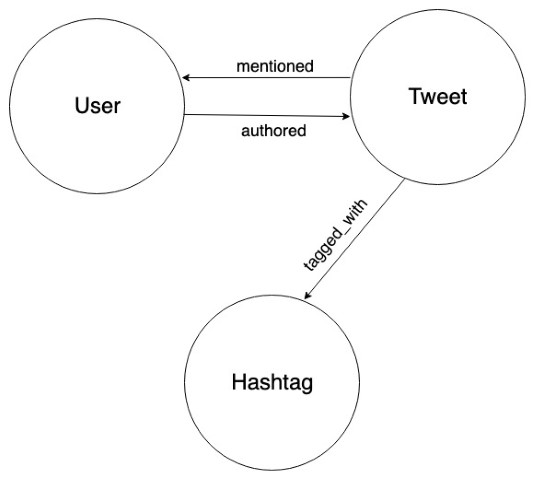
We used three real-life example tweets as a sample dataset and stored them in Dgraph using the above graph as a model.
Here is the sample dataset again if you skipped the previous tutorials. Copy the mutation below, go to the mutation tab and click Run.
{
"set": [
{
"user_handle": "hackintoshrao",
"user_name": "Karthic Rao",
"uid": "_:hackintoshrao",
"authored": [
{
"tweet": "Test tweet for the fifth episode of getting started series with @dgraphlabs. Wait for the video of the fourth one by @francesc the coming Wednesday!\n#GraphDB #GraphQL",
"tagged_with": [
{
"uid": "_:graphql",
"hashtag": "GraphQL"
},
{
"uid": "_:graphdb",
"hashtag": "GraphDB"
}
],
"mentioned": [
{
"uid": "_:francesc"
},
{
"uid": "_:dgraphlabs"
}
]
}
]
},
{
"user_handle": "francesc",
"user_name": "Francesc Campoy",
"uid": "_:francesc",
"authored": [
{
"tweet": "So many good talks at #graphqlconf, next year I'll make sure to be *at least* in the audience!\nAlso huge thanks to the live tweeting by @dgraphlabs for alleviating the FOMO😊\n#GraphDB ♥️ #GraphQL",
"tagged_with": [
{
"uid": "_:graphql"
},
{
"uid": "_:graphdb"
},
{
"hashtag": "graphqlconf"
}
],
"mentioned": [
{
"uid": "_:dgraphlabs"
}
]
}
]
},
{
"user_handle": "dgraphlabs",
"user_name": "Dgraph Labs",
"uid": "_:dgraphlabs",
"authored": [
{
"tweet": "Let's Go and catch @francesc at @Gopherpalooza today, as he scans into Go source code by building its Graph in Dgraph!\nBe there, as he Goes through analyzing Go source code, using a Go program, that stores data in the GraphDB built in Go!\n#golang #GraphDB #Databases #Dgraph ",
"tagged_with": [
{
"hashtag": "golang"
},
{
"uid": "_:graphdb"
},
{
"hashtag": "Databases"
},
{
"hashtag": "Dgraph"
}
],
"mentioned": [
{
"uid": "_:francesc"
},
{
"uid": "_:dgraphlabs"
}
]
},
{
"uid": "_:gopherpalooza",
"user_handle": "gopherpalooza",
"user_name": "Gopherpalooza"
}
]
}
]
}
Note: If you’re new to Dgraph, and this is the first time you’re running a mutation, we highly recommend reading the first tutorial of the series before proceeding.
Now you should have a graph with tweets, users, and hashtags, and it is ready for us to explore.
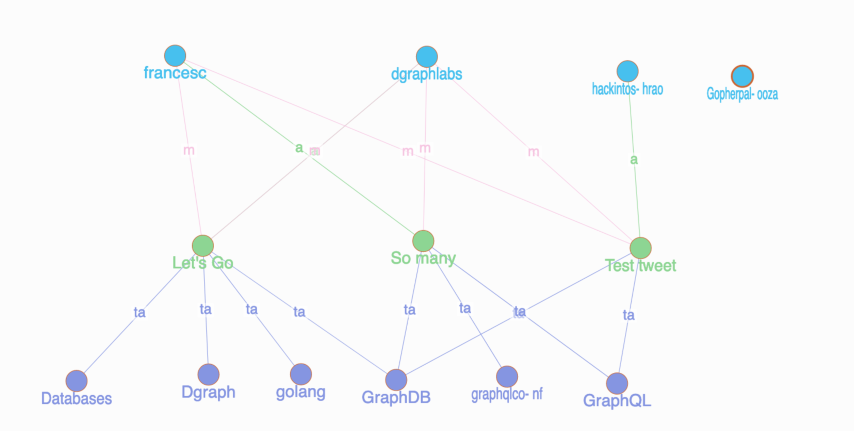
Note: If you’re curious to know how we modeled the tweets in Dgraph, refer to the fifth tutorial.
Before we show you the fuzzy search in action, let’s first understand what it is and how does it work.
Fuzzy search
Providing search capabilities on products or usernames requires searching for the closest match to a string, if a full match doesn’t exist.
This feature helps you get relevant results even if there’s a typo or the user doesn’t search based on the exact name it is stored.
This is exactly what the fuzzy search does: it compares the string values and returns the nearest matches.
Hence, it’s ideal for our use case of implementing search on the twitter usernames.
The functioning of the fuzzy search is based on the Levenshtein distance between the value of the user name stored in Dgraph and the search string.
Levenshtein distance is a metric that defines the closeness of two strings.
Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other.
For instance, the Levenshtein Distance between the strings book and back is 2.
The value of 2 is justified because by changing two characters, we changed the word book to back.
Now you’ve understood what the fuzzy search is and what it can do. Next, let’s learn how to use it on string predicates in Dgraph.
Implement Fuzzy Search in Dgraph
To use the fuzzy search on a string predicate in Dgraph, you first set the trigram index.
Go to the Schema tab and set the trigram index on the user_name predicate.
After setting the trigram index on the user_name predicate, you can use Dgraph’s
built-in function match to run a fuzzy search query.
Here is the syntax of the match function: match(predicate, search string, distance)
The match function takes in three parameters:
- The name of the string predicate used for querying.
- The search string provided by the user
- An integer that represents the maximum
Levenshtein Distancebetween the first two parameters. This value should be greater than 0. For example, when having an integer of 8 returns predicates with a distance value of less than or equal to 8.
Using a greater value for the distance parameter can potentially match more string predicates,
but it also yields less accurate results.
Before we use the match function, let’s first get the list of user names stored in the database.
{
names(func: has(user_name)) {
user_name
}
}
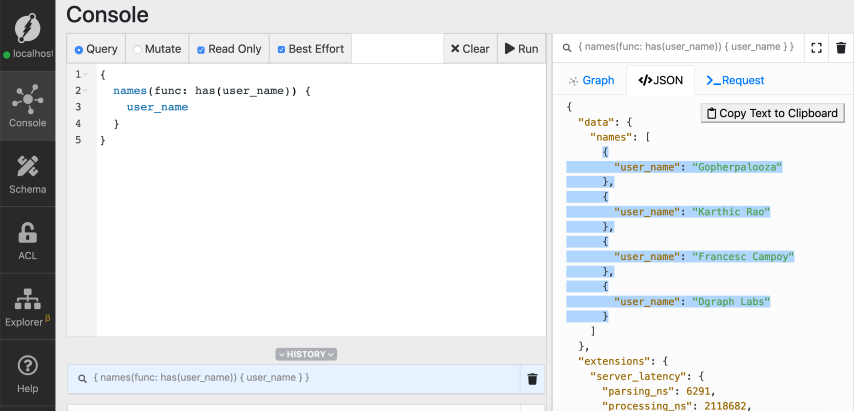
As you can see from the result, we have four user names: Gopherpalooza,
Karthic Rao, Francesc Campoy, and Dgraph Labs.
First, we set the Levenshtein Distance parameter to 3. We expect to see Dgraph returns
all the username predicates with three or fewer distances from the provided searching string.
Then, we set the second parameter, the search string provided by the user, as graphLabs.
Go to the query tab, paste the query below and click Run.
{
user_names_Search(func: match(user_name, "graphLabs", 3)) {
user_name
}
}
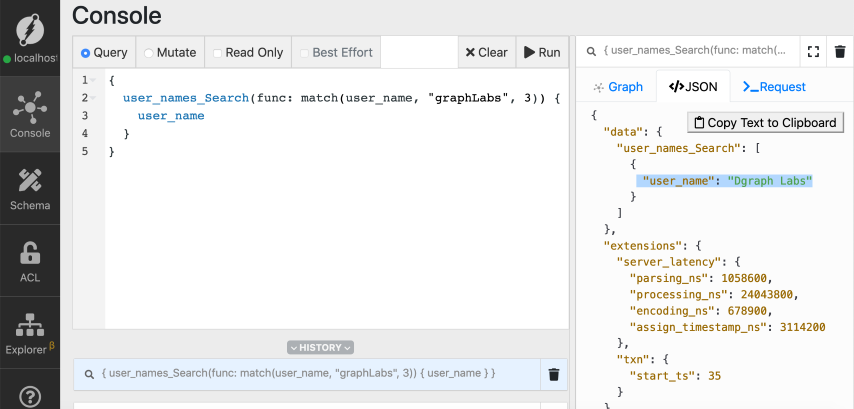
We got a positive match!
Because the search string graphLabs is at a distance of two from the predicate
value of Dgraph Labs, so we see it in the search result.
If you are interested in learning more about how to find the Levenshtein Distance between two strings, here is a useful site.
Let’s run the above query again, but this time we will use the search string graphLab instead.
Go to the query tab, paste the query below and click Run.
{
user_names_Search(func: match(user_name, "graphLab", 3)) {
user_name
}
}
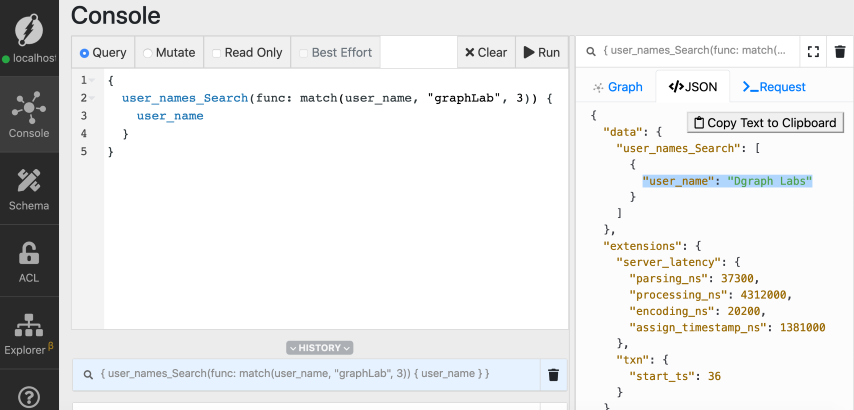
We still got a positive match with the user_name predicate with the value Dgraph Labs!
That’s because the search string graphLab is at a distance of three from the predicate
value of Dgraph Labs, so we see it in the search result.
In this case, the Levenshtein Distance between the search string graphLab and the
predicate Dgraph Labs is 3, hence the match.
For the last run of the query, let’s change the search string to Dgraph but keep the
Levenshtein Distance at 3.
{
user_names_Search(func: match(user_name, "Dgraph", 3)) {
user_name
}
}
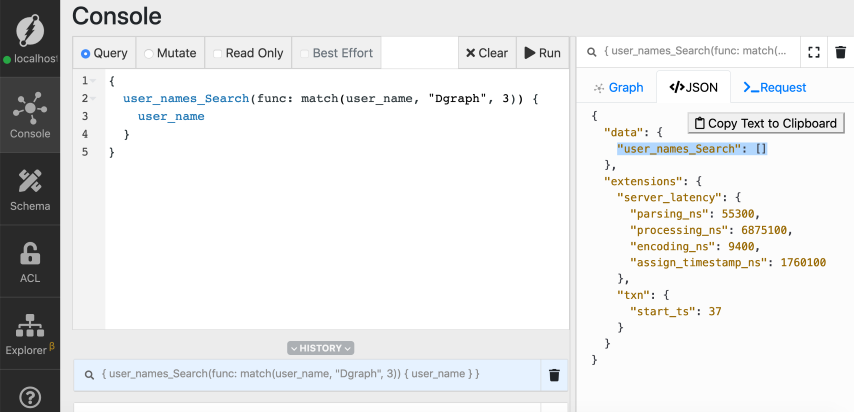
Now you no longer see Dgraph Labs appears in the search result because the distance
between the word Dgraph and Dgraph Labs is larger than 3. But based on normal
human rationales, you would naturally expect Dgraph Labs appears in the search
result while using Dgraph as the search string.
This is one of the downsides of the fuzzy search based on the Levenshtein Distance algorithm.
The effectiveness of the fuzzy search reduces as the value of the distance parameter decreases,
and it also reduces with an increase in the number of words included in the string predicate.
Therefore it’s not recommended to use the fuzzy search on the string predicates which
could contain many words, for instance, predicates which store the values for blog posts,
bio, product description and so on. Hence, the ideal candidates to use fuzzy search are
predicates like names, zipcodes, places, where the number of words in the string
predicate would generally between 1-3.
Also, based on the use case, tuning the distance parameter is crucial for the
effectiveness of fuzzy search.
Fuzzy search scoring because you asked for it
At Dgraph, we’re committed to improving the all-round capabilities of the distributed Graph
database. As part of one of our recent efforts to improve the database features, we’ve taken
note of the request on Github by one of
our community members to integrate a tf-idf score based text search. This integration will
further enhance the search capabilities of Dgraph.
We’ve prioritized the resolve of the issue in our product roadmap. We would like to take this opportunity to say thank you to our community of users for helping us make the product better.
Summary
Fuzzy search is a simple and yet effective search technique for a wide range of use cases.
Along with the existing features to query and search string predicates, the addition of
tf-idf based search will further improve Dgraph’s capabilities.
This marks the end of our three tutorial streak exploring string indices and their queries using the graph model of tweets.
Check out our next tutorial of the getting started series here.
Remember to click the “Join our community” button below and subscribe to our newsletter to get the latest tutorial right to your inbox.
Need Help
- Please use discuss.dgraph.io for questions, feature requests, bugs, and discussions.